3 things to look out for when using Spring Framework
I have for some years been involved in evolving Java Web applications that were written with early versions of the Spring Framework into more modern incarnations. When doing this I have constantly stumbled upon these issues that make the application hard to maintain and develop further.
1 Database schema is exposed via API
This is the issue that by far causes issues for the clients I work with.
The major problem is that the Spring framework tutorials drive developers to this pattern which might look like a simple and easy solutions and will look good in a presentation, but in the end, once the application matures, turns out to become a real headache both from a security and maintainability aspect.
A code smell of this is when you start asking questions like this:

There are multiple issues with exposing everything through the API layer.
From a security perspective the developer is no longer controlling what is exposed via the API from the application. All it takes for a developer to make a mistake is to add a new column to the database with some sensitive data and voilà, the sensitive information is immediately exposed via the end-point. You would need to have API schema tests that thoroughly tests that no unknown fields in the returned JSON are added to circumvent this. Most applications I've so far seen lack even the most basic tests, not to mention these kinds of corner-cases.
Another issue from a maintainability perspective is that when the database structure is directly exposed via the end-point, you are also locking the API down to whatever the database at that day happens to be.
As the application matures it is very likely you will need at some point a V2 of your API which returns a different JSON structure. This might occur when you add a new consumer of your service like another micro-service or a mobile client. The consumer of the service might have totally different needs of how your database schema looks like.
The way I've seen most developers solve this is to start adding extra transient fields to the existing entities returned by the repository. This of course affects V1 of the API that starts to get all this kind of extra information that it previously has not expected. Also the new clients will start getting all this extra information they need which was present in V1 of the API. The worst cases I've seen with this is that after you have added enough consumers and versions those entities need to be composed from almost every table in the database and the queries become slow and hard to understand.
Lets look at a better proven solution for this!
If you do not want to run into the above problems you cannot take the short path the Spring tutorials show. Forget about RestRepository, consider it an abstraction meant for demo purposes only.
You will need to use a layered approach to separate the data from the data representation returned via the API if you in the future want to have an better time maintaining and building on the API.
Instead, you could use a approach like this:
- Use a Repository for data layer only! Use it to fetch data only. A good indication of this is that your Entity classes does not contain any classes related to the JSON representation (like @JsonProperty) but only validation and query related annotations.
- Use a Service to mutate data, perform extra validations on the data. A good indication this is being done properly is that the service is the only class that accesses the repository. All data access goes through the service.
- Use a RestController to mutate data from entity returned by the service to the API JSON. Your RestController methods only return DTO's (Data-Transfer-Objects) and no entities. To convert between the entities and the DTO's use ModelMapper's TypeMaps! A good indication of good usage of DTO's is that the DTO does only contain JSON annotations and no database related annotations. Do not try to be smart and extend your Entity classes into DTO's ;)
Now, lets look at problems we had before and see how they can be solved with the above approach.
Now if a developer adds a new field to the database table it is exposed via the Entity class to the application but the API remains unchanged. The developer now have to manually add the field to the DTO if he wants to expose the information via the API as well. This forces the developer to think about what he is doing and weather it is a good idea or not.
Also the versioning problem goes away. Now that the API is using DTO's instead of Entity classes a new Controller or method can easily be added with a different DTO composed from the Entity. This means the application can provide different versions of the API without making changes to the data representation.
2 Data is only validated at database level or not at all
This is common scenario I also see where developers rely only on database constraints for data validation. Usually companies wake up to this only after there have been successful XSS or SQL injection attacks. At that point the data already is full of garbage and it will be really hard to get the data to become consistent and useful.
Another, leaner version of this is that validation is only done at one level, either at API or data level. The argument usually from developers is that it is wasteful to perform validation two times and validating what comes via the API should be enough.
However, I have seen it so many times that a simple coding mistake in the Controller or Service, or a security issue with the API validations has caused invalid data to end up in the database that could easily have been prevented.
If you have followed the solution in #1 to separate your API from your data layer then solving this should be as easy as applying the same validators to your DTO's as well as your Entity classes and always use @Valid for every input DTO in your Controller.
A good sign is that every field in both your DTO's and your Entity classes has some validator attached. This is especially true for String fields.
3 You don't need streams if you are not streaming data to the front-end or sending events
Most business applications today use REST as the main communication method both between services and between front-end and back-end. Unless you are working with a fully event driven architecture or you plan to move to one you should not pay much attention to the hype around streams today.
For applications related to processing numerical data (mostly IoT) they are useful, and most demos presented using streams are around this scenario where you have a numerical stream and you want to process that. By that is far from the CRUD application most businesses are using Spring for today and using the stream API to feed a CRUD with data and usually leads to these kinds of issues:
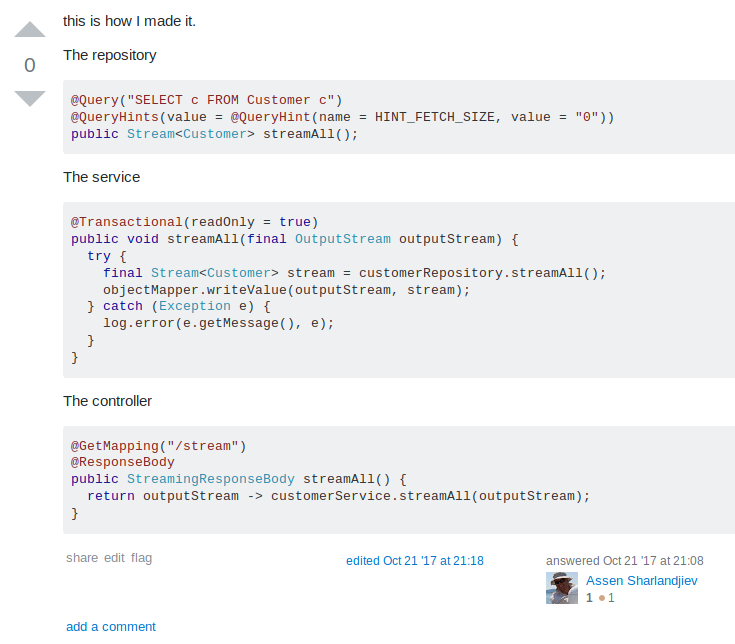
On the surface this might seem neat. But lets dig into that a bit.
In the repository you need to now rely on query hints that all database might or might not support. In this case the developer is messaging the database driver to return everything. Depending on how good the database driver is and how modern the database is (which might be pretty old in the enterprise) that might cause performance issues.
The service method no longer provides what type of entities it handles. While with non-streaming operations the service would return a list or Stream of entities, here we are providing an output stream only without any notion of what will happen to it. This would be a nightmare to test.
One key element with data persistance is transactions. Traditionally streaming and transactions have not worked together and only recently Spring has gain some support for them for MongoDB and R2DBC neither of which are majorly used for enterprise data. You can read more about the support in the Pivotal blog https://spring.io/blog/2019/05/16/reactive-transactions-with-spring. To summerize you lose transactions if you stream.
Finally, lets look at the controller. We are returning StreamingResponseBody instead of clear list or stream of entities. Again making testing harding and opaque.
Remember KISS. If your application does not rely on data streams you don't need the Spring streaming API. But by all means do not confuse this with Java Streams which can be useful when doing data transformations.
I hope these simple three observations will help you build applications that not only works today, but will allow your application to grow and evolve without major refactoring and security issues. To achieve this the best advice I can give you is that never use the latest sexy solution provided by the vendor if it does not give significant improvements that are easily modifiable in the future.